
Developer experiences from the trenches

Tue 16 August 2016 by Michael Labbé
tags code
If you are distributing a library, you have a responsibility to make it as trouble-free as possible to build and use. To do otherwise litters the Internet with a project that frustrates and consumes the time of potentially hundreds of programmers. (And when have you met a programmer with extra time?).
This presents an interesting building challenge: how do you create the most compatible build system while simultaneously burdening the user as little as possible?
Evidently, a lot of people turn to GNU Make. GNU Make, however, calls out to bash on Windows and uses Unix path slashes. Good luck getting that to work seamlessly with Visual Studio. The standalone GNU Make executable that the FSF hosts is over ten years old and is riddled with bugs. It hangs on fork() in Windows 10. Do not tell your users to download this. Do not tell your users to download msys2 or Cygwin so they can build your code if you respect their time.
Another option is CMake. Sadly, its sole installer download is 55MB, bundles QT and a full documentation set, and forces your users to parse syntax that they likely don’t understand. CMake generates projects with hardcoded paths which means the generated files can’t be reused.
SCons requires Python 2 to be present. We live in a Python 3 world; asking users to install a second Python implementation side by side is just rude.
In light of these options, Premake is a breath of fresh air. It’s not perfect, but you can download a one 1MB self-contained binary which consists of a small C-based engine and bundled Lua scripts. Premake generates build scripts with relative paths and gets you up and running in most popular environments very quickly.
But, wait! You can do even better. You can run Premake for your users, checking the generated projects into the repository. Nothing generated by Premake is specific to your computer’s setup. This removes two steps from building for your users: downloading Premake and running it. Awesome!
Premake has a nifty action feature, making it straightforward to script new actions, such as running itself multiple times to generate projects.
Doing so has a couple of subleties. Firstly, Premake is limited to generating project files in the directory that the premake5.lua script resides in. One directory with multiple builds in it is a mess. One option is to create a subdirectory per build type, then copy the premake5.lua script in there, run it, and then delete it. This sounds hacky, but it actually works without giving you any trouble.
Another thing to keep in mind when generating all of your Makefiles at once is that the Makefiles are operating system-specific. A Windows-based makefile will link different libraries, for instance. You need to generate build scripts-per platform.
In order to build from a subdirectory, you need to specify your paths relative from the generated subdirectory. This can be resolved succintly at the top of your premake5.lua script:
-- assumes the premake5.lua is in a subdirectory called "build" under
-- the project root.
local root_dir = path.join(path.getdirectory(_SCRIPT),"../../")
local build_dir = path.join(root_dir,"build/")
My library, Native File Dialog, has a Premake 5 Script action called “dist” which does exactly this. If I need to update the build scripts, I type premake5 dist and they are all refreshed. My library users need only run the generated builds. Feel free to copy the code for yourself.
Zero dependency building for users and a one meg standalone dependency for the package maintainer! This is the smallest price to pay for cross platform building I’ve ever come across.
Wed 06 July 2016 by Michael Labbe
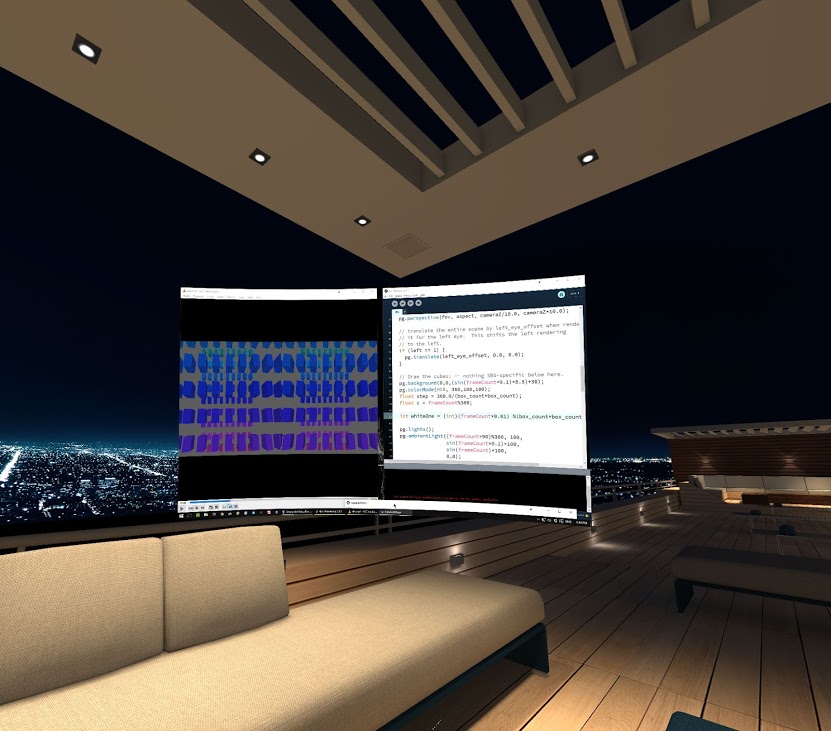
One of the really cool things about social VR is that a little technical know-how can go along way. Recently, I have been exploring social VR through BigScreen VR, an app that lets you see your monitor in the context of a large virtual room, shared by others. Imagine a virtual LAN party and you have a good idea about what’s going on.
Quietly, they dropped an SBS mode into the “Beta Features” menu. All of a sudden, it is possible to socially livecode 3D content in a VR world. And, it’s possible to do this with a top-to-bottom free software stack. How cool is that?
What is Side-By-Side (SBS) content? Check out this Youtube video to immediately get a sense of what is going on. In SBS videos, the image for each eye is encoded using half of the video framebuffer, with a small horizontal offset in the camera position. If you watch this in a side by side video app, each eye only sees the half of the video. Your brain is tricked into thinking it is seeing 3D objects. Leaning side to side even triggers a sense of parallax.
Because BigScreen shares your screen, you can develop software and test it right inside your VR headset. Enter Processing, a free visual coding environment with support for 3D rendering and offscreen framebuffers.
In order to render SBS content in Processing, you simply have to render to two offscreen framebuffers, offsetting them from each other.
Here is sample code with comments that demonstrates exactly how this works. You can copy and paste this into a Processing 3 IDE window and just run it.
If you are simply curious, this YouTube render shows what the Processing sketch looks like.
Sun 31 May 2015 by Michael Labbe
tags code
Git-svn is the bridge between Git and SVN. It is more dangerous than descending a ladder that into a pitch black bottomless pit. With the ladder, you would use the tactile response of your foot hitting thin air as a prompt to stop descending. With Git-Svn, you just sort of slip into the pit, and short of being Batman, you’re not getting back up and out.
There are plenty of pages on the Internet talking about how to use Git-svn, but not a lot of them explain when you should avoid it. Here are the major gotchas:
If you clone your Git-svn repo, say to another machine, know that it will be hopelessly out of sync once you run git svn dcommit. Running dcommit reorders all of the changes in the git repo, rewriting hashes in the process.
When pushing or pulling changes from the clone, Git will not be able to match hashes. This warning saves you from a late-stage manual re-commit of all your changes from the cloned machine.
Rebasing is systematic cherry picking. All of your pending changes are reapplied to the head of the git repo. In real world scenarios, this creates conflicts which must be resolved by manually merging.
Any time there is a manual merge, the integrity of the codebase is subject to the accuracy of your merge. People make mistakes — conflict resolution can bring bugs and make teams need to re-test the integrity of the build.
This might seem obvious, but think of this in context with the previous admonishment. If developers are committing to SVN as you perform time consuming rebases, you are racing to finish a rebase so you can commit before you are out of date.
Getting in a rebase, dcommit, fail, rebase loop is a risk. Don’t hold on to too many changes, as continuously rebasing calls on you to manually re-merge.
Here are a handful of scenarios where git-svn comes in handy and sidesteps these problems:
dcommit back to SVN.
Wed 07 January 2015 by Michael Labbe
tags biz
One hundred million people in VR at the same time isn’t a goal — it is the starting point.
The real goal is obtaining the inherent user lock-in related to hosting the most accurate simulation of materials, humans, goods and environments available. As we approach perfecting simulation of aspects of the real world, things that we used to do in the real world will now make sense to do in a VR context instead.
This upward trend will intersect another: real raw materials are increasingly strained, forcing the cost of production for goods beyond the access of the middle class. For activities that can be well simulated in VR but require hard to access materials to do in the real world, VR becomes a reasonable substitute.
Early VR 2.0 pioneers have talked about the opportunity to create a game that caused a mini-revolution like Doom did. That’s small potatoes. We are talking about a platform with control of artificial scarcity with the ability to make copies of goods for fractions of a penny. The winners in this game are the controllers of this exclusive simulation.
In this environment, Ferrari’s most valuable assets are going to be its trademarks many times over anything else it holds.
Dominoes will fall. VR headsets are the leaping off point, but not the whole picture — haptic controls, motion sensors, binaural audio interfaces, the list goes on. As each improves, more activities will make sense to perform in a virtual environment.
Looking back twenty years, referring to VR as a headset is going to seem trite. The world is changing from a place that “has Internet” to a place that is the Internet, and for the first time, you only have to extrapolate the fidelity of current simulation technologies to see it.
