
Developer experiences from the trenches

Sat 14 January 2023 by Michael Labbe
tags code
So, you’re programming in C/C++ and your editor is live-checking your code, throwing up errors as you type them. Depending on your editor you’re either getting red underlines or some sort of marker in the margins that compels you to change it. But how does this source code processing engine work, and what can you do when things go off the rails when you attempt something like a unity build?
You may have configured your editor to use a language server called clangd, or it may have been configured for you.
Clangd also offers other benefits, such as go-to-definition and code completion. It runs as a subprocess of your editor, and that means it’s doing its indexing work off the main thread as you would hope.
Clangd can be configured to work with VSCode and Emacs amongst others.
You’re coding along and need to include a bunch of files from a library, so you add a new include path to your build with -Isome_lib/. Unfortunately, clangd doesn’t nkow that you build with this, so a bunch of ugly, incorrect compile errors pop up in your editor.
If you employ your Google-fu, you land on a page that says that Clangd lets you specify your compile flags in a yaml file called .clangd. But, wait! There is a better way. You really want to automate this, or you’ll have to maintain two sets of all your compile flags, which sounds like one of the least enjoyable things you could possibly fritter your time away on.
The good news is that Clangd, alternatively, reads in a compile database, which is just a JSON-structured list of the commands needed to compile each file in a given way. There are plenty of tools that can generate a compile database automatically. For example, if you can output Ninja Build files, you are one step away:
ninja -t compdb > compile_database.json
Clangd recursively searches up the tree to find this file, and uses it to try and compile your files. If a source file exists in your codebase but isn’t in the compile database, it will infer the flags needed to compile it from other commands in adjacent files in this directory. This is most likely what you want, and it’s a great starting point.
You should run this command as a post-build step, or after updating your source repo in order to automatically update your compile database so you never have to worry about keeping your compile flags in sync again.
Sometimes your on-the-fly error checking is too quick on the draw. It tells you about warnings you’d rather only see when you’re compiling. Warning about unused functions is one such example — you declare a function as static and intend to call it. But, before you have a chance to call it, it throws a distracting error. Let me finish typing, Clangd!
One option is to use a compile database post processor that ingests the Clang database that is spat out from Ninja, letting you make the tweaks you need. Now you have automation and customization.
I wrote a compile database post processor that you pipe your output through. Now your command looks like:
ninja -t compdb | \
cleanup-compdb > compile_commands.json
Let’s say you want to disable the warning for unused functions. cleanup-compdb can append a flag for that to each compile command:
ninja -t compdb | \
cleanup-compdb \
--append-arguments="-Wno-unused-function" \
> compile_commands.json
Let’s start by defining the problem.
You have a c “root” file that #includes one or more “sub” files which produce a single translation unit. Clangd now deftly handles the root file and locates the includes. However, Clangd has no concept of c source that is not a stand alone translation unit, so the sub files generate more benign errors than you can count.
Clangd doesn’t have support for unity builds. However, we can instruct it to resolve the necessary symbols as if the sub files were each their own translation unit for error checking purposes.
To illustrate this technique let’s define the root translation unit as root.c, and the sub units as sub0.c, sub1.c, and so on.
An additional file root.unity.h will be created that has all of the common symbols for the translation unit.
Create a root.unity.h file that starts with #pragma once and includes all common symbols in the translation unit, including system headers and forward declarations.
Create root.c which includes root.unity.h before anything else. Doing anything else in this file is entirely optional.
Create sub0.c and start it off with #pragma once and then include root.unity.h.
Include sub0.c at the bottom of root.unity.h.
Repeat steps 3 and 4 for any other sub-files in the unity build.
This has the following results:
root.c compiles and includes sub0.c and ignores the second include of root.unity.h that comes from sub0.c because that file starts with #pragma once.root.c, the previously described compilation works similarly and everything just works.sub0.c as the faux-main translation unit, it includes root.unity.h and all symbols resolve, thus fixing the litany of errors.One hiccup remains. Clangd now emits this warning:
warning: #pragma once in main file
This is but a hiccup for us if we are using a compilation database postprocessor as described in problem 2. Simply append -Wno-pragma-once-outside-header to the list of warnings we want to ignore.
Jumping to symbols in an IDE and getting accurate compilation previews is a problem that has been imperfectly solved for decades, even with commercial plugins in Visual Studio. This blog post proposes a few tweaks to the language server Clangd which, in exchange for paying an up-front effort cost, automates the maintenance of a compilation database that can be tweaked to suit your specific needs.
In taking the steps described in this blog post, you will gain the knowhow to adapt the existing tools to a wide range of C/C++ codebases.
I propose a new technique for unity builds in Clangd that operates without the inclusion of any additional compiler flags. If you are able to factor your unity builds to match this format, it is worth an attempt.
Mon 27 December 2021 by Michael Labbe
tags code
Sure, we call it printf debugging, but as projects get more complex, we aren’t literally calling printf. As our software is adopted we progress to troubleshooting user’s logs. If we’re granted enough success we are faced with statistically quantifying occurrences from many users logs via telemetry.
This is best served by structured logging. There are many formal definitions of structured logs, but for our purposes a simple example will do. Say you have this log line:
Player disconnected. Player count: 12
A structured log breaks fields out to make further processing and filtering trivial. This example uses JSON but it can be anything consistent that a machine can process:
{
"file": "src/network.c",
"line": 1000,
"timestamp": "1640625081",
"msg": "Player disconnected.",
"player_count": 12
}
The structured version looks like a message that can be processed and graphed by a telemetry system, or easily searched and filtered in a logging tool.
Coming from backend development where structured logging is expected and common, I wanted this function in my next game client. Because client performance is finite, I sought a way to assemble these messages using the preprocessor.
In practice, a fully structured message can be logged in one single function call without unnecessary heap allocation, unnecessary format specifier processing or runtime string concatenation. Much of the overhead in traditional loggers can be entirely avoided by building the logic using the C preprocessor.
The rest of this post illustrates how you might write your own structured logger using the C preprocessor to avoid runtime overhead. Each step takes the concept further than the one before it, building on the previous implementation and concepts.
Rather than supply a one-size-fits-all library, I suggest you roll your own logger. Stop when the functionality is adequate for your situation. Change the functionality where it does not fit your needs.
The most basic logger just calls printf(). For modest projects, you’re done! Just remember to clean up your logs before you ship.
It is useful to wrap printf() in a variadic macro, which can be toggled off and on to reduce spam and gain performance on a per-compilation unit basis.
As of C99, we have variadic macros. The following compiles on Visual C++ 2019, clang and gcc with --std=gnu99.
#define LOGF(fmt, ...) fprintf(stdout, fmt, __VA_ARGS__);
#define LOG(comment) puts(comment);
Why do we need a special case LOG() that is separate from LOGF()? Unfortunately, having zero variadic arguments is not C99 compliant and, in practice, generates warnings. For conciseness, the rest of this post only provides examples for LOGF(). However, a full implementation would handle both the zero argument and the non-zero argument cases wholly.
Having logs print to stdout, also append to disk or submit to a telemetry ingestor are all useful scenarios. Changing where logs are emitted can be reduced to a series of preprocessor config flags.
// config
#define LOG_USE_STDIO 1
#define LOG_USE_FILE 1
// implementation
#if LOG_USE_STDIO
# define LOG__STDIO_FPRINTF(stream, fmt, ...) \
fprintf(stream, fmt, __VA_ARGS__);
#else
# define LOG__STDIO_FPRINTF(stream, fmt, ...)
#endif
#if LOG_USE_FILE
# define LOG__FILE(stream, fmt, ...) \
fprintf(stream, fmt, __VA_ARGS__); \
fflush(stream);
#else
# define LOG__FILE(stream, fmt, ...)
#endif
Note the call to fflush() ensures the stream is correctly written to disk in the result of an unscheduled process termination. This can be essential for troubleshooting the source of the crash!
Now we have two macros LOG__STDIO_FPRINTF() and LOG__FILE() which either log to the respective targets or do nothing, depending on configuration. The double underscore indicates the macro is internal, and not part of the logging API. Replace the previous LOGF() definition with the following:
#define LOGF(fmt, ...) \
{ \
LOG__STDIO_FPRINTF(stdout, fmt, __VA_ARGS__); \
LOG__FILE(handle, fmt, __VA_ARGS__); \
}
Opening handle prior to calling LOGF() is an exercise left up to the implementer.
Limiting logging to higher severity messages is useful for reducing spam. Traditional logging packages call into a variadic function, expending resources before determining the log level does not permit the log line to be written.
We can do better — our logging system simply generates no code at all if the log level is too low.
#define LOG_LEVEL_TRACE 0
#define LOG_LEVEL_WARN 1
#define LOG_LEVEL_ERROR 2
#if !defined(LOG_LEVEL)
# define LOG_LEVEL LOG_LEVEL_TRACE
#endif
The test for LOG_LEVEL being pre-defined allows a user to control the log level on a per-compilation unit basis before including the logging header file. This is extremely useful for getting detailed logs for only the section of code you are currently working on.
With this in mind, delete the LOGF definition, and replace it with the following:
#define LOG__DECL_LOGLEVELF(T, fmt, ...) \
{ \
LOG__STDIO_FPRINTF(stdout, T ": " fmt, __VA_ARGS__); \
LOG__FILE(handle, T ": " fmt, __VA_ARGS__); \
}
#if LOG_LEVEL == LOG_LEVEL_TRACE
# define LOG_TRACEF(fmt, ...) LOG__DECL_LOGLEVELF("TRC", fmt, __VA_ARGS__);
#else
# define LOG_TRACEF(fmt, ...)
#endif
#if LOG_LEVEL <= LOG_LEVEL_WARN
# define LOG_WARNF(fmt, ...) LOG__DECL_LOGLEVELF("WRN", fmt, __VA_ARGS__);
#else
# define LOG_WARNF(fmt, ...)
#endif
#if LOG_LEVEL <= LOG_LEVEL_ERROR
# define LOG_ERRORF(fmt, ...) LOG__DECL_LOGLEVELF("ERR", fmt, __VA_ARGS__);
#else
# define LOG_ERRORF(fmt, ...)
#endif
Adding or changing log levels is an exercise left up to the user. Do what works for you.
Note the obscure T ": " fmt syntax. Rather than pay the overhead of invoking snprintf(), or allocating heap memory to prefix the log line with “TRC”, “WRN” or “ERR”, we use preprocessor concatenation to generate a single format string at compile time.
At this point, you should be able to write the following code:
#define LOG_LEVEL 0
#include "log.h"
LOG_TRACEF("Hello, %d worlds!", 42);
and see the log line
TRC: Hello, 42 worlds!
on stdout, and in your log file.
C gives us macros for the file and line each log line was generated on. Before we go on to support specific structured fields, we can already generate a structured log with four fields:
At the beginning of this post a JSON-structured log was used as an example of a structured log. However, there is a runtime cost to escaping logged strings in order to produce valid JSON in all cases that we would like to avoid. Consider:
LOG_TRACE("I said \"don't do it\"");
Unless processed, this would produce the ill-formatted JSON string
"I said "don't do it""
Rather than generate structured JSON, another logging format is used, which can be postprocessed into JSON with a small script if necessary.
/^\t[a-zA-Z0-9]+:\x20/0x20 0x1A 0x0A is encountered./.+\x20\x1A\n/0x1A 0x1A. /\x1A\x1A$/.This results in a structured log message which is machine-parsable, but is also human readable on popular Linux UTF-8 terminals, as well as DOS codepage 437 (the DOS Latin US codepage). Unless your log messages contain the highly obscure byte sequences described above (unlikely!), we do not need to do any runtime escaping, even for newlines.
A structured log is one long string that is concatenated in the preprocessor. Here we provide a mechanism to let the user choose between flat and structured with a preprocessor flag.
// config
#define LOG_USE_STRUCTURED 1
// implementation
#define LOG__EOL "\x20\x1A\n"
#define LOG__EOM "\x1A\x1A\n"
#define LOG__FLAT(file, line, level, msg) \
level " " file ":" line " |" msg "\n"
#define LOG__STRUCTURED(file, line, level, msg) \
level LOG__EOL \
"\tfile: " file LOG__EOL \
"\tline: " line LOG__EOL \
"\tmsg: " msg LOG__EOM "\n"
#if LOG_USE_STRUCTURED
# define LOG__LINE(file, line, level, msg) \
LOG__STRUCTURED(file, line, level, msg)
#else
# define LOG__LINE(file, line, level, msg) \
LOG__FLAT(file, line, level, msg)
#endif
Now a call to LOG__LINE() generates either a flat or structured string which can be passed into a printf-style format specifier parameter. We redefine LOG__DECL_LOGLEVELF() as follows:
#define LOG__XSTR(x) #x
#define LOG__STR(x) LOG__XSTR(x)
#define LOG__DECL_LOGLEVELF(T, fmt, ...) \
{ \
LOG__STDIO_FPRINTF(stdout, \
LOG__LINE(__FILE__, LOG__STR(__LINE__), #T, fmt), \
__VA_ARGS__); \
\
LOG__FILE(handle, \
LOG__LINE(__FILE__, LOG__STR(__LINE__), #T, fmt), \
__VA_ARGS__); \
}
Note the use of LOG__STR(__LINE__) is necessary to stringify __LINE__, which is an integral constant. Because we concatenate it at compile time, it must be stringified.
Structured logging of custom fields pushes the boundaries of what can be done by C preprocessing. Internally, we run a precompile step that:
Building such a script and hooking it up as a precompile step is out of scope for this post. However, it is possible to perform this work incurring a single snprintf() at runtime.
Despite all of these changes and improvements, a logging call to print to stdout will still result in a single function call. To test that, we view the preprocessed output of a LOG_TRACEF() call generated with clang -E:
// logging call in source
LOG_TRACEF("Hello %d", 42);
// output of clang's c preprocessor (newlines added)
{
fprintf(stdout, "\"TRC\"" "\x20\x1A\n"
"\tfile: " "main.c" "\x20\x1A\n"
"\tline: " "10" "\x20\x1A\n"
"\tmsg: " "Hello %d\n"
"\x1A\x1A\n" "\n", 42);; ;
};;
Success — we can see only one call being made and it’s to the library function fprintf to log the message. On Windows console it looks something like this:
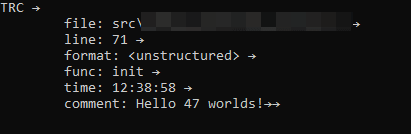
The little arrows are the end-of-line and end-of-message markers, essential for further machine processing.
As explained, further processing of logs into JSON may be a necessary step before telemetry ingestion. This Python script accepts structured logs streamed from stdin. It outputs properly formatted JSON.
Here is sample code assembled from the snippets in this post.
All of the sample code in this blog post and in the linked gist are Copyright © 2021 Frogtoss Games, Inc., and are free to use and modify under the terms of the MIT license.
Sat 23 February 2019 by Michael Labbe
tags code
Kubernetes is so good at maintaining a user-facing veneer of a stable service that you might not even know that you are periodically crashing until you set up log aggregation and do a keyword search for panic. You can miss crash cues because pods spin up so transparently.
Okay, so your application can crash. You are using Go. What can you do about it? In practice, here are the steps we have found useful:
SIGSEGV gracefully.SIGTERM messages.
If you write a C program and do not explicitly handle SIGSEGV with signal(2), the receipt of SIGSEGV terminates the offending thread.
Go is different from C. Go’s runtime has a default panic handler that catches these signals and turns them into a panic. Defer, Panic and Recover on the official blog covers the basic mechanism.
SIGSEGV (“segmentation violation”) is the most common one. Go will happily compile this SIGSEGV-generating code:
var diebad *int
*diebad++ // oh, no
The full list of panic reasons is described in the official panic.go source.
Not every signal produces a Go panic — not by a long shot. Linux has over 50 signals. Version 7 had 15 different signals; SVR4 and 4.4BSD both have 31 different signals. Signals are a kernel interface exposed in userspace, and a primary means for processes to contend with their role in the larger operating system.
Let’s go over the non-panic inducing signals and discuss what they mean to our Kubernetes-driven Go program:
Unignorable signals: SIGKILL and SIGSTOP can’t be ignored. They are provided by the kernel as a surefire way of killing a process. If received, the process terminates without warning and we have to rely on logging coming from external sources. It is not recommended to use unignorable signals in automating your process restarts.
Flow-related signals: Many signals can be classified as supporting thread execution. These include SIGCONT and SIGPIPE. They do not interact with Kubernetes and we can safely ignore them or reserve them for any process-specific needs that come up.
Kubernetes-Generated Signals. Kubernetes sends SIGTERM to PID 1 in your container thirty seconds before shutting down a pod. If you weren’t trapping this previously (and also not using a preStop hook), you are missing an opportunity to gracefully shut down your pod. By default, SIGTERM terminates the process in a Go program. The more aggressive SIGKILL is sent to your pod if it is still running after the grace period.
We’ve established that crashing signals in Go are received by its runtime panic handler, and that we want to override this behaviour to provide our own logging, stack tracing, and http response to a calling client.
In some environments you can globally trap exceptions. For instance, on Windows in a c++ environment you can use Structured Exception Handling to unwind the stack and perform diagnostics.
Not so in Go. We have one technique: defer. We can set up a defer function near the top of our goroutine stack that is executed if a panic occurs. When there, we can detect if a panic is currently in progress. There are a number of gotchas with this technique:
defer does not run if os.Exit() is called. Make sure all error paths out of your process call panic or use runtime.Goexit().defer (and recover) operate on goroutines, not processes. If you set a defer to run in main and then spawn a goroutine which panics, the defer will not be called.We can use the latter trait to our advantage in our web service, providing a generic panic handler that logs, and a second panic handler inside the goroutine that responds to a web request that returns 500 error to the user.
The global panic handler is your opportunity to employ your logger to use your logger to provide all relevant crash diagnostics that occur outside of responding to an HTTP request:
//
// Sample code to catch panics in the main goroutine
//
func main() {
defer func() {
r := recover()
if r == nil {
return // no panic underway
}
fmt.Printf("PanicHandler invoked because %v\n", r)
// print debug stack
debug.PrintStack()
os.Exit(1)
}()
}
Most (if not all) Go RESTful packages use a per-request Goroutine to respond to incoming requests so they can perform in parallel. The top of this stack is under package control, and so it is up to the RESTful package maintainer to provide a panic handler.
go-restful defaults to doing nothing but offers an API to trap a panic, calling your designated callback. From there, it is up to you to log diagnostics and respond to the user. Check with your RESTful package for similar handlers.
go-restful’s default panic handler (implemented in logStackOnRecover) logs the stack trace back to the caller. Don’t use it. Write your own panic handler that leverages your logging solution and does not expose internals at a crash site to a client.
Okay, at this point we are logging crash diagnostics, but what about amicable pod termination? Kubernetes is sending SIGTERM and because we are not yet trapping it, it is causing our process to silently exit.
Consider the case of a DB connection over TCP. If our process has open TCP connections, a TCP connection sits idle until one side sends a packet. Killing the process without closing a TCP socket results in a half-open connection. Half-open connections are handled deep in your database driver and explicit disconnection is not necessary, but it is nice.
It avoids the need for application-level keepalive round trips to discover a half-open connection. Correctly closing all TCP connections ensures your database-side connection count telemetry is accurate. Further, if a starting pod initializes a large enough database connection pool in the timeout window, it may temporarily exceed your max db connections because the half-closed ones have not timed out yet!
//
// Sample code to trap SIGTERM
//
func main()
sigs := make(chan os.Signal, 1)
signal.Notify(sigs, syscall.SIGTERM)
go func() {
// before you trapped SIGTERM your process would
// have exited, so we are now on borrowed time.
//
// Kubernetes sends SIGTERM 30 seconds before
// shutting down the pod.
sig := <-sigs
// Log the received signal
fmt.Printf("LOG: Caught sig ")
fmt.Println(sig)
// ... close TCP connections here.
// Gracefully exit.
// (Use runtime.GoExit() if you need to call defers)
os.Exit(0)
}()
}
You may also want to trap SIGINT which usually occurs when the user types Control-C. These don’t happen in production, but if you see one in a log, you can quickly recognize you aren’t looking at production logs!
At this point we have deeply limited the number of ways your application can silently fail in production. The resiliency of Kubernetes and the default behaviours of the Go runtime can sweep issues under the rug.
With just a few small code snippets, we are back in control of our exit conditions.
Crashing gracefully is about leaving a meaningful corpse for others to find.
Thu 05 July 2018 by Michael Labbé
tags code
Intellect, the ability to focus in on a problem and sheer time committed to the craft of programming are critical and pretty obvious elements that make a programmer good. Having these things on your side is partly luck and partly an expensive time commitment. However, I believe there are further traits that can be developed through habit-forming practice that make a programmer excellent.
Some programmers transcend being merely good; they are highly effective. This often becomes apparent when you see them becoming the team’s de facto problem solver, or when they reliably design and implement excellent-fit solutions, topping their previous attempts.
In the teams I’ve participated in and built I have found three traits that recur in highly effective programmers. When I find even one of them they often go on to live up to great promise. Any one of them is a strong tell, and more is a sign of a programmer with serious potential to be impactful.
The first trait is intellectual curiosity. When you find someone who tinkers because they are curious about new results you are engaging someone who has internalized the impetus for pioneering solutions. Internalization of curiosity is key because it is the surest driver of tangential exploration. A programmer who has exercised solutions to problems they dreamt up themselves out of pure interest in discovery has strengthened their abilities in excess of the rigours of standard professional performance. Professional programming makes you strong enough to stand tall in full gravity. Intellectual curiosity exceeds that; it is like training with a weight belt on.
The second trait is tenacity. Tenacity is the sworn enemy of “Cool, it works! We’re done!”. Those who internalize this trait never spitball their way to a final solution. If multiplying by negative one solves the problem but they don’t know why, they remove it and figure out why the sign inversion makes everything seemingly work. Inherent to this behaviour is the inclination to traverse underneath abstractions. Making it work is no longer the quest; the search is for a deeper understanding, one that makes the answer readily apparent. Illuminate the problem with a hard-earned understanding of the facts and the rest is small muscle movements.
An example of tenacity is spending three weeks tracking down a memory leak in ostensibly mature system libraries. Working through source, compiling it yourself, pouring over machine code, examining the compiler, and then reading your processor instruction manual. Rewriting portions of libc to verify results. Thermal imaging in your data center. Whatever it takes.
The final trait is a willingness to self criticize. Most programmers eventually have the experience of looking at code from a few years back and cringing. While syntax choices evolve, the cringe truly comes from a looking-in view of a naive problem solver doing their best and missing their mark. When a priori derived solutions are mismatched with the present understanding of a problem, personal growth is felt at a gut level.
An unprompted individual who consistently criticizes their own solutions is going to blossom quickly. Any valuable solution space is enormous, and the ability to criticize from a positive vantage point is the natural habitat of an always improving programmer.
Those are the three traits I’ve seen that suggest a programmer is going to be promising and impactful. Next time I am going to ponder the question that affects your effectiveness more than anything else: How do you decide what to work on?
